Mehrere Mutationen pro Generation
Das Einfachmodell aus dem letzten Kapitel ist zwar mit einer einzigen Mutation relativ überschaubar, leider aber auch relativ realitätsfremd. Tasten wir uns einen Schritt weiter in Richtung Wirklichkeit und untersuchen, welche Konsequenzen mehr als eine Mutation nach sich ziehen. Mit mehr als einer Mutation kommt man vielleicht schneller voran, zumindest solange sie in der Mehrheit positiv ausfallen. Denn leider erhöhen sie auch die Gefahr, dass es zu Verschlechterungen kommt. Aber vielleicht kann man diesen Effekt wieder über eine höhere Zahl von Individuuen innerhalb einer Generation ausgleichen.
Mehrere Mutationen bei einem einzelnen Individuum
Das folgende Schema versucht darzustellen, was passiert, wenn ein Individuum mehrere Mutationen hintereinander erfährt. Das Individuum besteht wieder einmal aus Bits, von denen bereits Bits den korrekten Wert besitzten, während die restlichen Bits noch den falschen Zustand aufweisen. Die Wahrscheinlichkeit dieses Ausgangszustandes ist 1 (100%). Ganz einfach, weil er ist, wie er ist. Danach kommt es hintereinander zu mehreren Mutationen. Bezüglich der Art und Weise, wie diese geschehen, muss man aber eine Festlegung treffen:
- Man kann sich das so vorstellen, dass die einzelnen Mutationen nacheinander stattfinden und die einzelnen Mutationen dabei jedesmal vollkommen zufällig an irgendeiner Stelle des Gemons zuschlagen. Das beinhaltet auch die Möglichkeit, dass ein gerade gekipptes Bit gleich noch einmal mutiert, seinen Zustand also mehrfach ändern kann. Diese Methode nennt man "Ziehen mit Zurücklegen".
- Man kann die ganze Sache aber auch als "Ziehen ohne Zurücklegen" implentieren, etwa wie man es vom Lotto kennt. Jede einzelne Mutation findet dann garantiert an einer anderen Position im Genom statt.
Welche Variante man verwendet ist letzlich egal, es ist nur eine Frage der Konvention. Ich benutze im folgenden die erste Variante, also "Ziehen mit Zurücklegen". Die Wahl ist eher zufällig passiert, weil das Simulationsprogramm dadurch geringfügig einfacher zu programmieren war. Man muss nicht eigens Buch darüber führen, welche Bitpositionen noch mutieren dürfen. Numerisch dürfte der Unterschied weitgehend vernachlässigbar sein, da ich mich hier auf ein Problem mit sehr vielen Parametern aber sehr wenigen Mutationen beschränke. Formeltechnisch sollte der Unterschied größer sein, wer will kann es gerne selber ausprobieren.
Die erste Mutation führt entweder zu einer Verbesserung oder zu einer Verschlechterung:
- Verbesserung:
- Verschlechterung:
Mit zwei, zumeist unterschiedlichen Wahrscheinlichkeiten haben wir jetzt entweder ein Individuum, das um ein Bit schlechter, oder eines das um ein Bit besser ist als das Ausgangsindividuum. Bislang ist das noch genau das gleiche, wie wir es bereits im letzten Kapitel unterschucht haben. Was macht jetzt aber die zweite Mutation daraus?
Als Erstes kann aus dem schlechteren der beiden Individuen ein noch schlechteres entstehen. Die Wahrscheinlichkeit dafür ist die, dass wir es überhaupt mit dem schlechten Individuum zu tun haben, multipliziert mit der Wahrscheinlichkeit, dass die zweite Mutation wieder ein "gutes" Bit erwischt. Die Wahrscheinlichkeit für letzteres ist aber jetzt etwas geringer als bei der ersten Mutation, denn die Zahl der guten Bits hat sich bereits um eins reduziert.
In analoger Form erhält man aus dem besser Individuen mit einer gewissen Wahrscheinlichkeit ein noch besseres. Der interessantere Fall ist aber der Term in der Mitte. So wie sich das schlechtere der beiden Individuen durch Mutation wieder verbessern kann, wie sich auch das bessere wieder durch eine ungeeignete Mutation verschlechtern kann. Die jeweiligen Teilwahrscheinlichkeiten erhält man wieder wie im obigen Fall. Die Gesamtwahrscheinlichkeit für den Fall, dass es nach zwei Mutationen gar keine Verbesserung gab, ergibt sich aus der Summe dieser beiden Teilwahrscheinlichkeiten.
Es ist leicht einzusehen, das sich das Schema mit der nächsten Mutation wieder um ein Spalte in beide Richtungen vergrößern wird. Es hat sehr viel mit dem altbekannten Yang-Hui-Dreieck zu tun. Leider ist es durch die Multiplikationen mit den Einzelwahrscheinlichkeiten etwas schief und in Richtung von stärker gewichtet. Um es für beliebige Mutationszahlen auswerten zu können, kann man die folgende octave-Funktion verwenden:
% Calculate the probabilities for a single individual
% and many mutations.
%
% Arguments
% n - total number of bits
% ng - inital number of good bits
% m - number of mutations per generation
%
% Returns:
% delta - change relative to ng0
% p - probability of respective change
function [delta, p_single] = probabilities_single(n, ng, m)
% calculate the probalitites for a single individuum with m mutations
% it is essentially Pascal's triangle, weighted by ng / n
delta = -m - 1 : 1 : m + 1;
p_single = zeros(1, length(delta));
p_single(int16(length(delta) / 2)) = 1;
pb = (ones(1, length(delta)) * ng + delta) / n;
pg = (ones(1, length(delta)) * (n - ng) - delta) / n;
pb(1) = 0.;
pb(length(delta)) = 0.;
pg(1) = 0.;
pg(length(delta)) = 0.;
for i = 1 : m
p_single = shift(pg .* p_single, 1) + shift(pb .* p_single, -1);
endfor
% shorten the vector by eliminating 0 entries
i = 1;
while (i <= length(delta))
if p_single(i) == 0
delta = [delta(1 : i - 1) delta(i + 1 : length(delta))];
p_single = [p_single(1 : i - 1) p_single(i + 1 : length(p_single))];
endif
i++;
endwhile
endfunction
Diese Funktion liefert als Ergebnis zwei Vektoren zurück. Einen für die Änderung der "guten" Bits relativ zum Ausgangszustand, sowie die zugehörigen Wahrscheinlichkeiten . Wobei anzumerken ist, dass die octave-Funktion Zeilen mit einer Wahrscheinlichkeit von null im Hinblick auf höhere Ausführungsgeschwindigkeiten eliminiert. Das heißt die Länge der Vektoren wird im allgemeinen kürzer sein, als in der folgenden Langfassung als Formel gezeigt:
Probieren wir erst einmal einige einfache Fälle aus, die wir schon kennen. Wir greifen auf das Beispiel des Bildes aus dem letzten Kapitel zurück, das aus 500 x 333 Bildpunkten zu je 24 Bit verfügte. Schauen wir uns zunächst die Ursuppe bei an. Testen wir der Reihe nach die Fälle:
- Gar keine Mutation,
- eine Mutation und
- zwei Mutationen.
>> n=500*333*24
n = 3996000
>> ng = n/2
ng = 1998000
Das Resultat der Funktion probabilities_single() besteht aus zwei Vektoren. Der erste beinhaltet die Änderungen relativ zu sowie die zugehörigen Wahrscheinlichkeiten. Im Falle von null Mutationen erhalten wir kein überraschendes Ergebnis. Es gibt mit 100% Wahrscheinlichkeit keine Änderung:
>> [d, p] = probabilities_single(n, ng, 0);
>> d
d = 0
>> p
p = 1
Auch der Fall mit einer Mutation liefert ein bekanntes Ergebnis. Weil wir uns auf dem Niveau der Ursuppe bewegen, gibt es mit 50% Wahrscheinlichkeit eine Änderung zum Schlechteren, mit 50% zum Besseren und zwar um ein Bit in die eine oder andere Richtung:
>> [d, p] = probabilities_single(n, ng, 1);
>> d
d =
-1 1
>> p
p =
0.50000 0.50000
And now to something completely different: Zwei Mutationen! Auch hier liegt das Ergebnis wegen der Ursuppe im Bereich des zu erwartenden, nämlich den Koeffizienten des Pascalschen Dreiecks (freilich normiert auf eine Summe von eins):
>> [d, p] = probabilities_single(n, ng, 2);
>> d
d =
-2 0 2
>> p
p =
0.25000 0.50000 0.25000
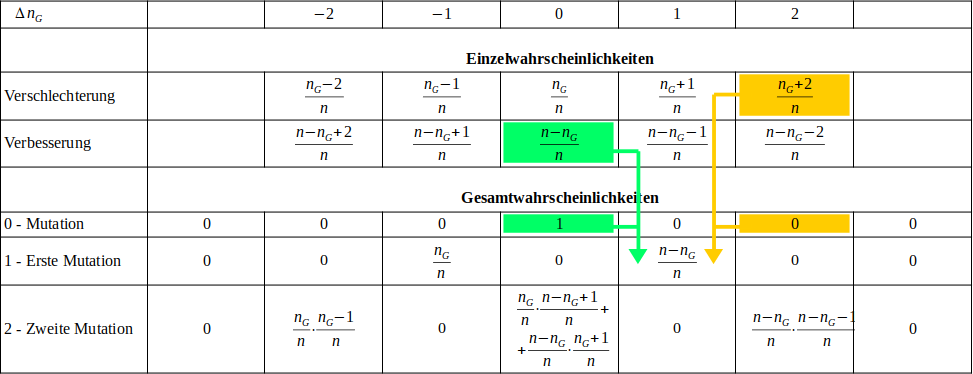
Jetzt aber in die Vollen: 5 Mutationen und 10 Mutationen an einem Individuum. Ausserdem für verschiedene Verhältnisse von (10%, 25%, 50%, 75% und 90%). Die möglichen Änderungen reichen von einer Verschlecherung um 5 Bits bis zu einer Verbesserung um 5 Bits. Deutlich zu erkennen ist, dass dass oberhalb der 50% die Wahrscheinlichkeit für negative größer ist als für positive Veränderung. Genau spiegelbildlich sieht es unterhalb der 50% aus. Wir begegnen hier wieder dem Problem, dass blinde Mutationen ein System immer nur der Ursuppe näherbringen. Sind mehr als 50% der Bits im "Gut"-Zustand, dann geht es abwärts, sind es weniger als 50% verbessern Mutationen die Situation. Die Evolution wird ein System über dieses Niveau nur entwickeln, wenn wir die Selektion hinzunehmen.
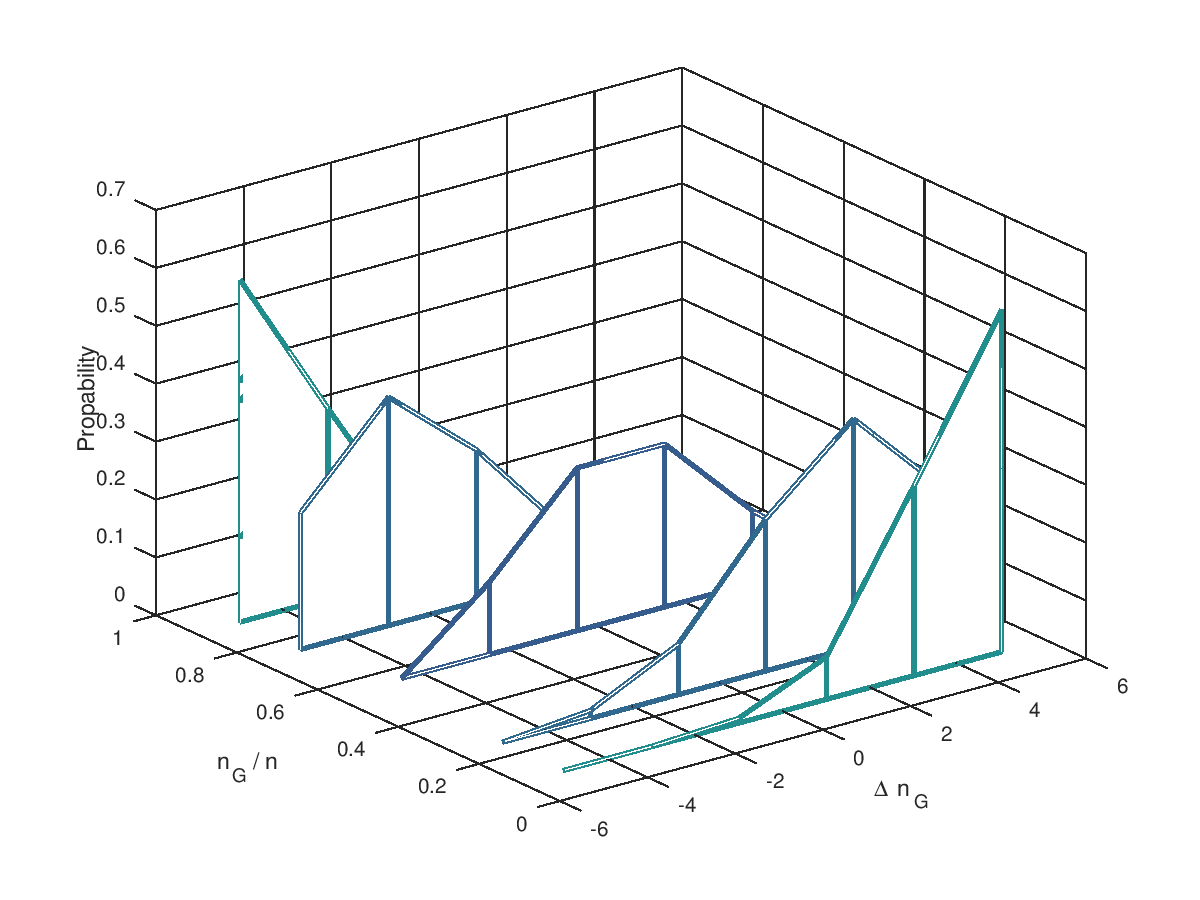
(Wie entstehen die Grafiken? => diesem Link folgen.)
Mehr als ein Individuum
Und genau damit machen wir jetzt weiter: Mit einer Kombination aus Mutationen UND Selektion Praktisch bedeutet das aber , dass unser Individuum mehr als einen Nachkommen haben muss, nämlich mindestens zwei oder mehr, genau hat. Jedes einzelne dieser Nachkommen hat Mutationen, die sich aber von Individuum zu Individuum unterscheiden. Im folgenden Schema ist das dargestellt. Die einzelnen Individuen können gegenüber ihrem Vorgänger in günstigsten Fall Verbesserungen aufweisen. Es können aber auch weniger sein. Der schlechteste Fall wäre, dass es zu Verschlechterungen gekommen wäre. Jeder dieser Änderungen ist eine Einzelwahrscheinlichkeit zugeordnet, die nach der im vorigen Abschnitt gezeigten Methode zu berechnen ist. Da alle Individuen von ein und demselben Vorgänger abstammen, sind die verfügbaren Möglichkeiten und Wahrscheinlichkeiten bei allen gleich.
Man kann die auftretenden Änderungen innerhalb einer Generation in einer Matrix zusammenfassen. Jede der Spalten steht für ein Individdum. Das selbe kann man mit den zugeordneten Wahrscheinlichkeiten machen.
Das Problem besteht nun darin, die beiden Matrizen so umzuformen, das wir am Ende wieder zwei einzelne Vektoren erhalten:
Dazu ein erster Ansatz: Jede Zelle in der ersten Spalte Matrix der Wahrscheinlichkeiten repräsentiert ein bestimmtes Ereignis. Diese Ereignis tritt unabhängig von den Ereignissen in den Spalten 2 etc. bis auf. Die Wahrscheinlichkeit für eine bestimmte Kombination von Ereignissen aus Spalte 1, 2 etc. ergibt sich jeweils aus dem Produkt der Einzelwahrscheinlichkeiten. Wir müssen also jede Kombination von Werten aus Spate 1, 2 etc. bilden und jeweils das Produkt bilden.
Was aber machen wir mit dem berechneten Produkt? Wir müssen es einer bestimmten Klasse zuordnen und die diversen Produkte, die der gleichen Klasse zugeordnet sind, aufsummieren. Als Klase benutzen wir die Änderung der korrekt gesetzten Bits . Erinnern wir uns an unsere recht einfache Form von Selektion: Der Beste überlebt. Das bedeutet aber, dass die berechnete Wahrscheinlichkeit der größten Änderung von zuzuordnen ist:
Das folgende octave-Skript geht genauso vor:
% Calculate the number of good bits for each generation
%
% Arguments
% n - total number of bits
% ng - inital number of good bits
% m - number of mutations per generation
% s - population size
%
% Returns:
% delta - change relative to ng0
% p - probability of respective change
function [delta, p] = probabilities_multiple(n, ng, m, s)
% calculate the probalitites for a single individuum with m mutations
% it is essentially Pascal's triangle, weighted by ng / n
[delta, p_single] = probabilities_single(n, ng, m);
% sum the probilities of s individuals
p = zeros(1, length(delta));
i = ones(1, s);
notAtEnd = true;
while (notAtEnd)
p(max(i)) += prod(p_single(i));
for k = 1 : length(i)
i(k) = i(k) + 1;
if i(k) <= length(delta)
break;
else
i(k) = 1;
if k == length(i)
notAtEnd = false;
endif
endif
endfor
endwhile
endfunction
Leider skaliert der Rechenaufwand in Abhängigkeit von der Zahl der Mutationen und Populationsgröße denkbar schlecht. Wir müssen Teilprodukte berechnen und jedes Teilprodukt erfordert Multiplikationen. Insgesamt also Multiplikationen. Wir brauchen einen kostensparenderen Ansatz.
Das gelingt, indem wir uns auf die Berechnung des Ergebnisses für eine Populationsgröße von zwei beschränken. Dieses Rechenergebnis, das uns zunächst Multiplikationen kostet, benutzen wir indem wir im nächsten Schritt in analoger Form die Wahrscheinlichkeit für eine Populationsgröße von 3 benutzen, was uns wieder nur kostet. Und so weier, bis wir bei einer Populationsgröße von s angelangt sind. Das ganze skaliert jetzt nur noch in der Größenordnung . Quadratisch anstatt exponentiell ist eine deutliche Verbesserung, wer will kann den Laufzeitunterschied Unterschied mit einer Populationsgröße von 100 ausprobieren:
% Calculate the number of good bits for each generation
%
% Arguments
% n - total number of bits
% ng - inital number of good bits
% m - number of mutations per generation
% s - population size
%
% Returns:
% delta - change relative to ng0
% p - probability of respective change
function [delta, p] = probabilities_multiple(n, ng, m, s)
% calculate the probalitites for a single individuum with m mutations
% it is essentially Pascal's triangle, weighted by ng / n
[delta, p_single] = probabilities_single(n, ng, m);
p = p_single;
Delta = max(delta', delta);
for i = 1 : s-1
P = p_single' * p;
for j = 1 : length(delta);
p(j) = sum(sum((Delta == delta(j)) .* P));
endfor
endfor
endfunction
Auswirkungen einer größeren Population
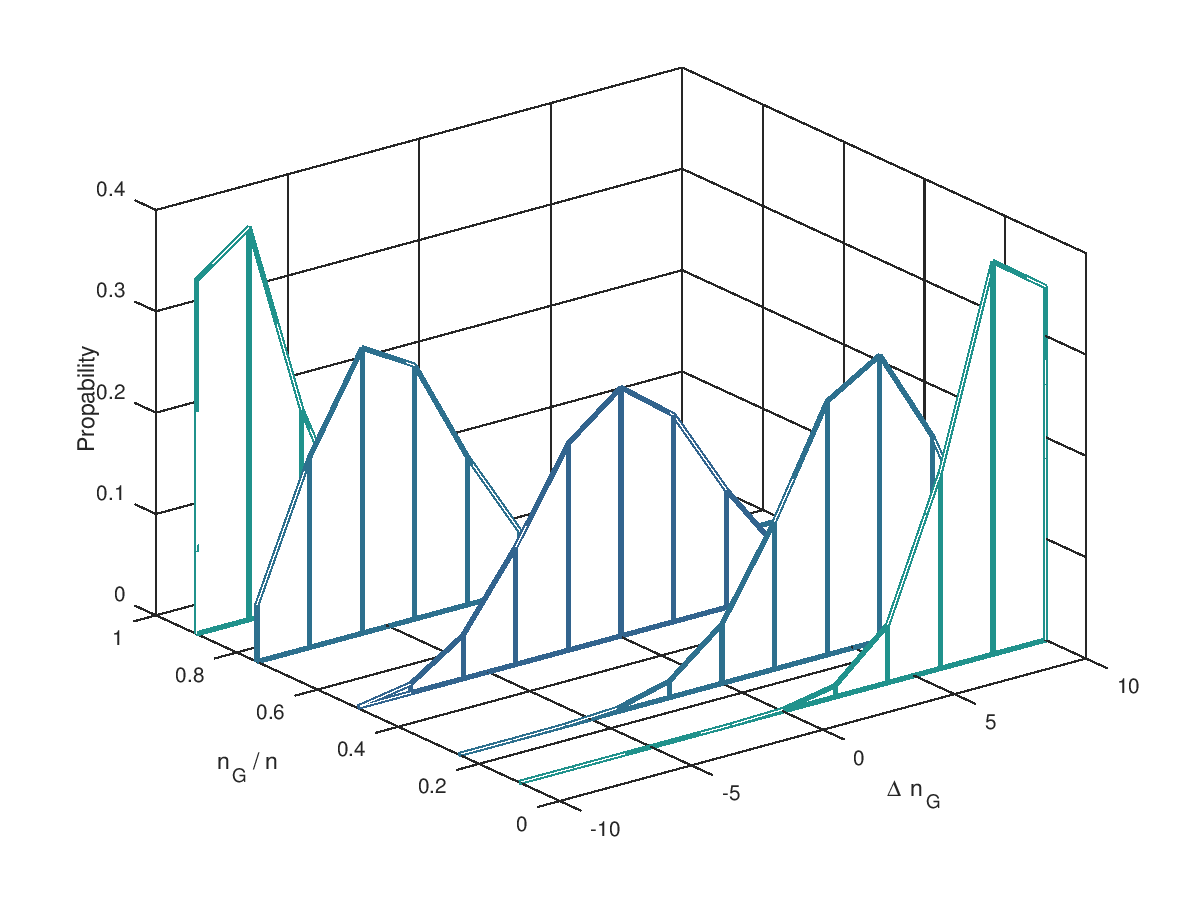
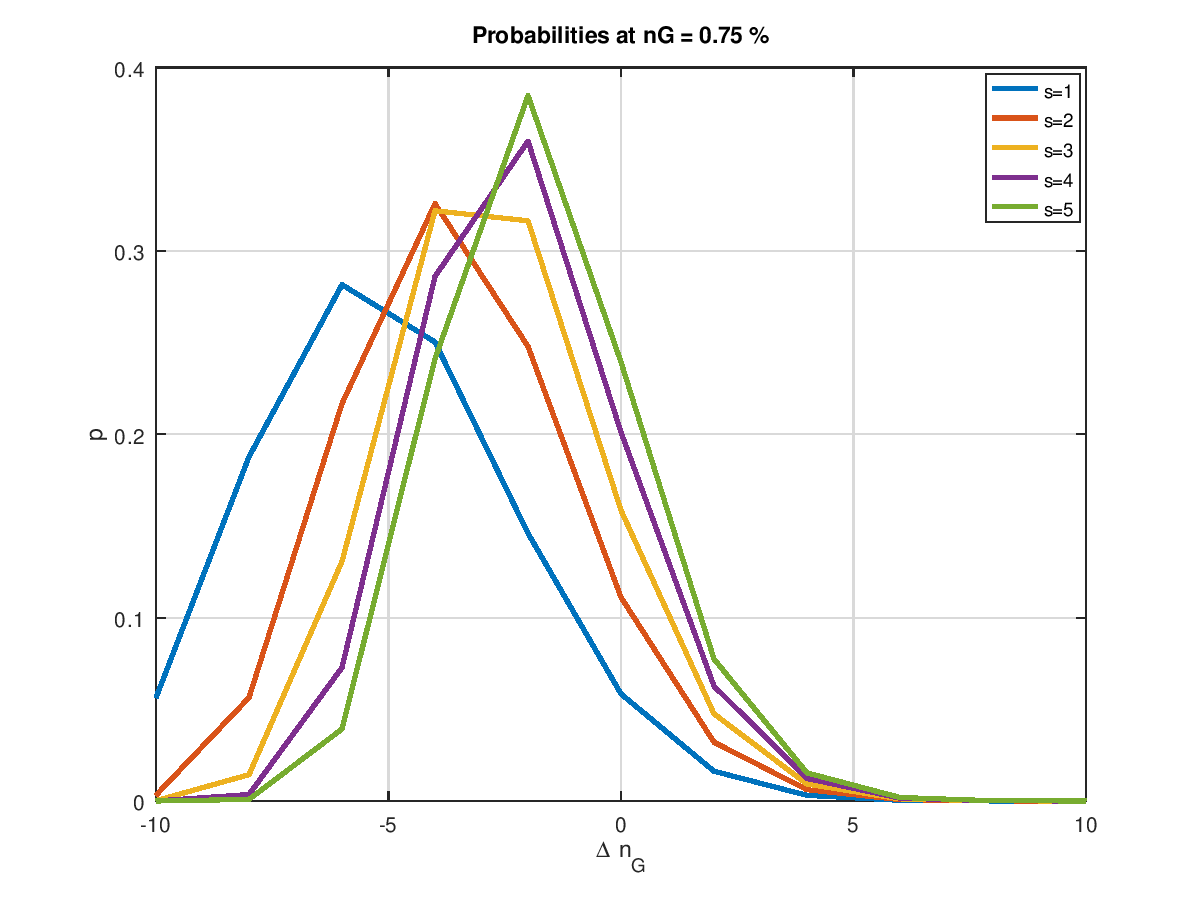
Damit haben wir jetzt das Rüstzeug, um den Einfluss der Populationsgröße zu ermitteln. Die folgende Grafik zeigt examplarisch für unsere 4 Mio. Bits und 10 Mutationen, was in der Ursuppe passiert, wenn man die Populationsgröße von 1 bis 5 steigert. Die am weitesten links angesiedelte Wahrscheinlichkeitsverteilung ist die mit einer Populationsgröße von eins. Sie ist symmetrisch zur Nulllinie. Verbesserungen und Verschlechterungen halten sich hier die Waage. Wir kennen das schon von weiter oben. Eine Zunahme der Populationsgröße verschiebt die Wahrscheinlichkeitsverteilung nach rechts hin zu positiven . Umso größer die Population, umso weiter die Verschiebung nach rechts.
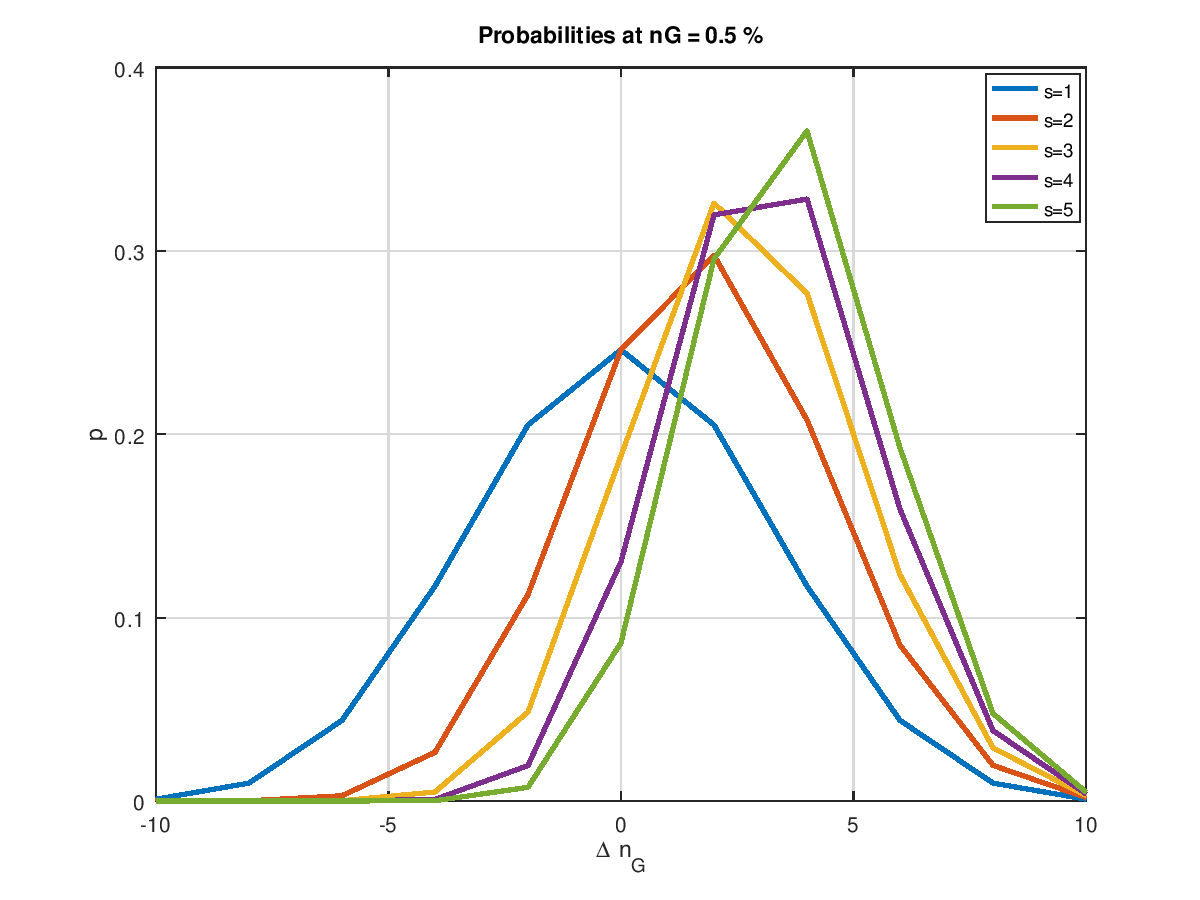
Schauen wir uns das Ganze an einer anderen Stelle an, nämlich bei 75%. Auch hier zeigt sich der Trend in Richtung höherer Wahrscheinlichkeit. Jedoch reicht keine der im Bild gezeigten Populationsgrößen aus, den Schwerpunkt der Wahrscheinlichkeitsverteilung in den positiven Bereich zu verlagern. Das heißt nichts anderes, als dass dieser so einfache Optimierungsalgorithmus niemals in diese Region vorstoßen wird. Und würde man den Startpunkt der Optimierung, egal ob mit Absicht oder durch Zufall in diesen Bereich legen, so würde der Algorithmus über kurz oder lang (eher kurz) in Richtung kleinerer laufen.
Geschwindigkeit der Optimierung
Wo liegt aber genau die Grenze? Am einfachsten finden wir die, indem wir die Geschwindigkeit der Optimierung berechnen (wobei hier unter Geschwindigkeit wieder der zu erwartende Fortschritt pro Generation verstanden werden soll):
Als octave Funktion sieht das wie folgt aus:
% Calcualte the speed of optimisation
%
% n number og bits to optimise
% ng number of bits with correct value
% m number of mutations
% s population size
function v = speed(n, ng, m, s)
[delta, p] = probabilities_multiple(n, ng, m, s);
v = sum(delta .* p);
endfunction
Plottet man die Geschwindigkeit in Abhängigkeit von für verschiedene Populationsgrößen und Mutationsraten, so erhält man eine Kurvenschar, bei denen man umittelbar die Grenzen der Optimierbarkeit erkennt: Dort wo eine Kurve die Nullinie durchstößt ist Schluss! Die folgenden zwei Grafiken zeigen das für einerseits die minimal sinnvolle Zahl von Mutation pro Generation, nämlich 1 und einer etwas höheren Zahl von 10, was angesichts eines "Erbguts" von 4 Mio. Bits eigentlich auch noch nicht viel ist.
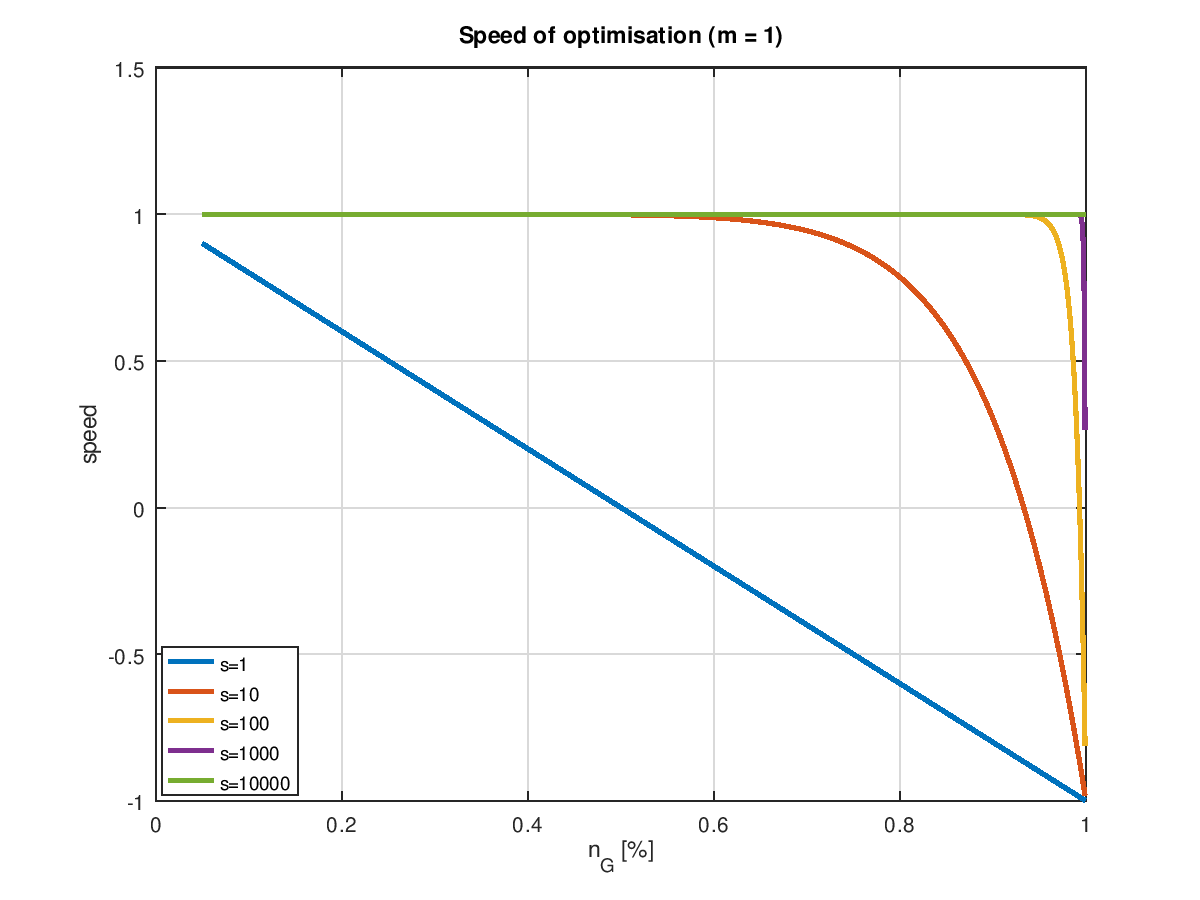
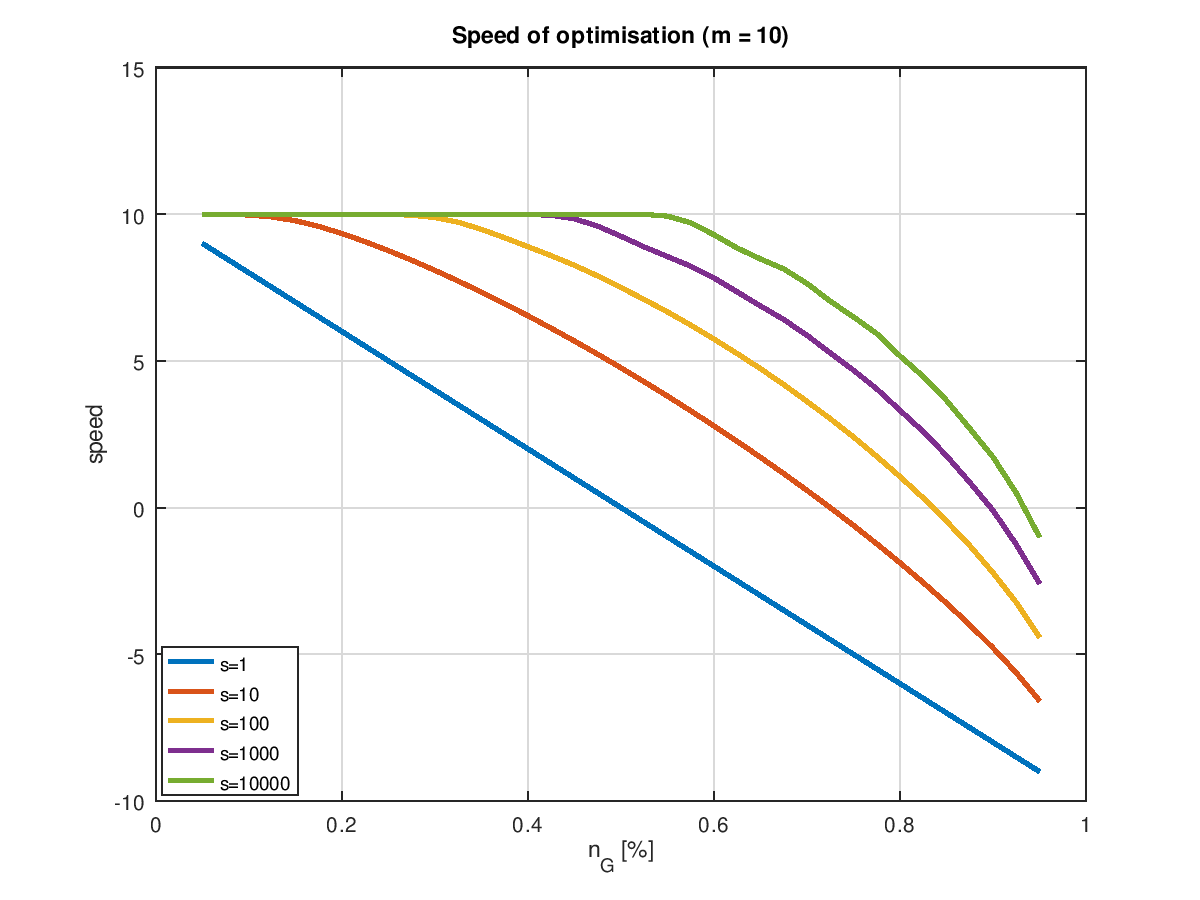
Bei einer einzigen Mutation zeigt sich das aus dem letzten Kapitel bekannte Verhalten. schon eine moderate Erhöhung der Populationsgröße führt dazu, dass die volle Optimierungsgeschwindigkeit lange erhalten bleibt und ganz besonders auch ein hoher Endwert ereicht wird. Wobei "volle Geschwindigkeit" hier aber auch nur 1 Bit pro Generation bedeutet. Mit mehr Mutationen ist natürlich mehr drin. Offensichtlich bezahlt man aber die höhere Geschwindigkeit mit einem sehr hohen Preis. Die im Idealfall möglichen 10 Verbesserungen pro Generation sind selbst bei sehr großen Populationsgröße allenfalls im Bereich der Ursuppe möglich. Und der Bereich positiver Optimierungsraten wird schon relativ schnell verlassen. Es sei denn, man steigert die Populationsgröße ins fast Unermessliche.
Grenzen der Optimierung
Mittels der gerade berechneten Geschwindigkeit der Optimierung ist es jetzt auch ein Leichtes das bestmögliche Optimierungsergebnis in Abhängigkeit von der Zahl der Mutationen und der Populationsgröße zu berechnen. Schlichtes Nullsetzen der Geschwindigkeit reicht. Leider geht das nicht mehr analytisch (eine geschlossene Formel für die Geschwindigkeit kann ich nicht anbieten), aber octave bietet für die numerische Nullstellensuche die Funktion fzero() an. Grafisch aufgetragen sieht man deutlich den Einfluss der Zahl der Mutationen: Zu viele davon ramponieren ziemlich nachhaltig das Optimierungsergebnis und ist auch durch eine höhere Populationsgröße kaum noch auszugleichen. mit einer einzigen Mutation pro Generation könnte man ein fast perfektes Ergebnis erzielen. Höhere Mutationsraten enden mit einem suboptimalen Ergebnis. Mutationen und Rückmutationen verursachen ein ständiges Rauschen in allen Bits, auch bei denen, die bereits schon einmal den korrekten Wert hatten.
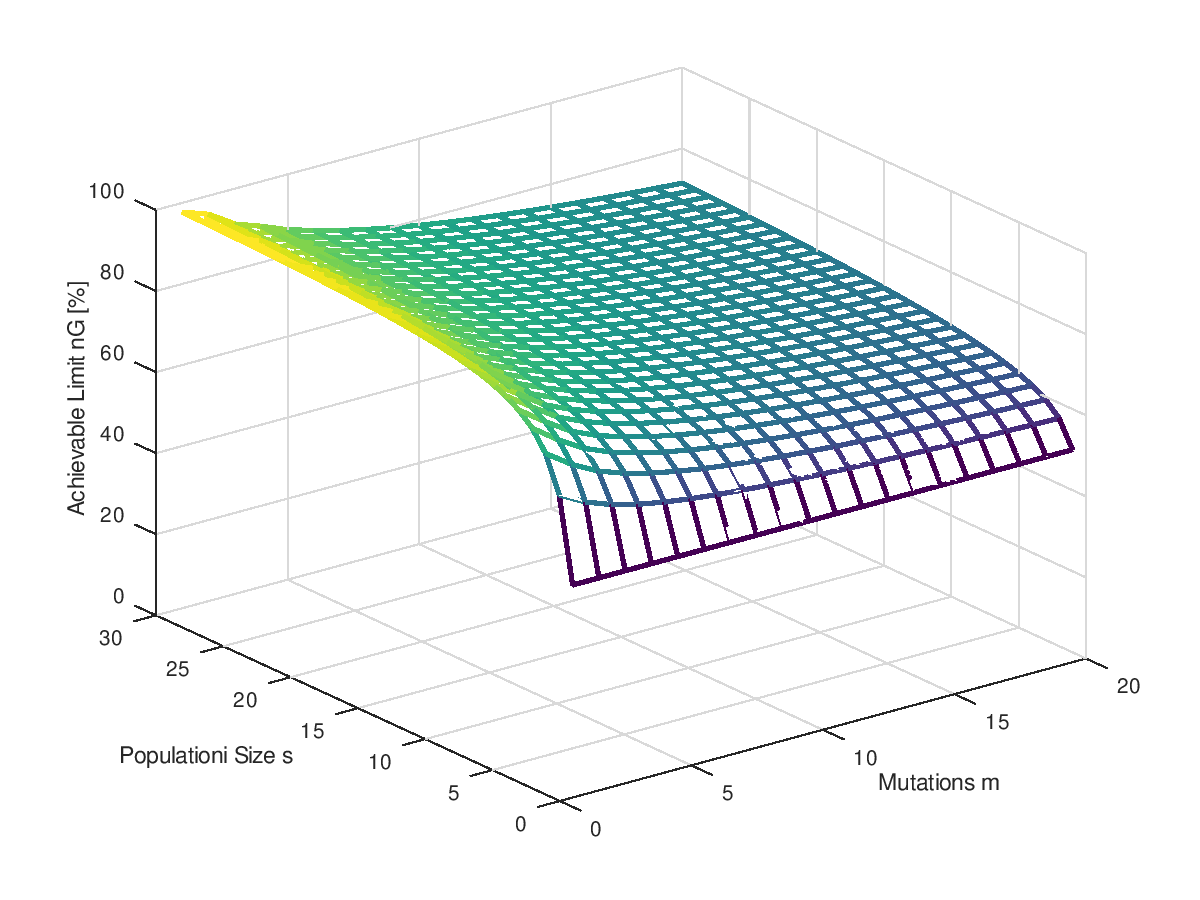
Es ist schwer zu sagen, ob es für jedes einen Grenzwert gibt, der nicht überschritten werden kann, oder ob mit einer massiven Erhöhung der Populationsgröße nicht doch die 100% asymptotisch erreicht werden können. Der Gaudi halber zeigt das nächste Bild noch einmal den gleichen Sachverhalt, nur mit weitaus größerer Populationsgrößen bis 1000. Und nicht als Oberflächenplot sondern als Kurvenschar. Ob es Asymptoten gegeben könnte, ist schwer zu sagen. Beweisen könnte ich es ohnehin nicht.
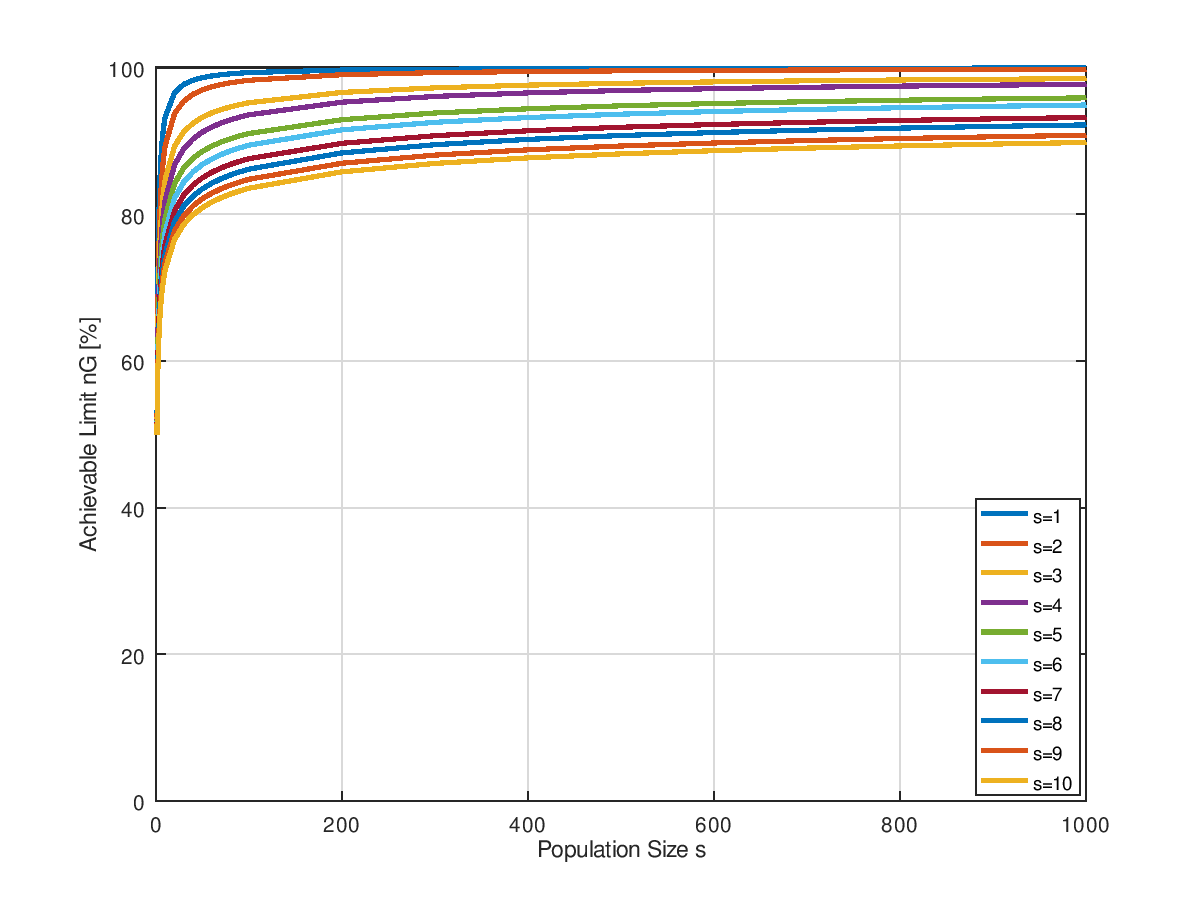
Ja stimmtes denn überhaupt?
Nach den ganzen kombinatorischen Betrachtungen stellt sich jetzt die Frage, ob denn unsere (simulierte) Evolution sich tatsächlich so verhält wie vorhergesagt. Eine stichprobenartige Überprüfung ist im nächsten Bild dargestellt. Es zeigt als dünne, schwarz ausgezogene Linien die Vorhersagen für drei willkürlich gewählte Kombinationen aus Mutationen pro Generation und Populatationsgrößen. Die dicken, farbigen Linien zeigen das Ergebnis der jeweiligen Versuche, mittels unseres Programmes PictureOptimizer ein Bild mit ebendiesen Parametern zu "züchten". Vorher noch ein kurzer Blick auf den octave-Code, mit dessen Hilfe die Vorhersage erzeugt wurden. Letzlich ist es nur ein simples Aufsummieren der schon weiter oben errechneten Geschwindigkeiten:
% Calculate the progress of optimization
%
% n: number of bits
% m: number of mutations per individual
% s: number of individuals per generation
% i_max: number generations to calculate
%
% returns:
% ng:
function ng = nGood(n, m, s, i_max)
ng = zeros(1, i_max);
ng(1) = n / 2;
for i = 1 : 1: i_max - 1
[d, p] = probabilities_multiple(n, ng(i), m , s);
ng(i + 1) = ng(i) + sum(d .* p);
endfor
endfunction
Aufgerufen wird diese Funktion mit:
n = 500*333*24;
ng = nGood(n, 5, 3, 500000);
plot(ng);
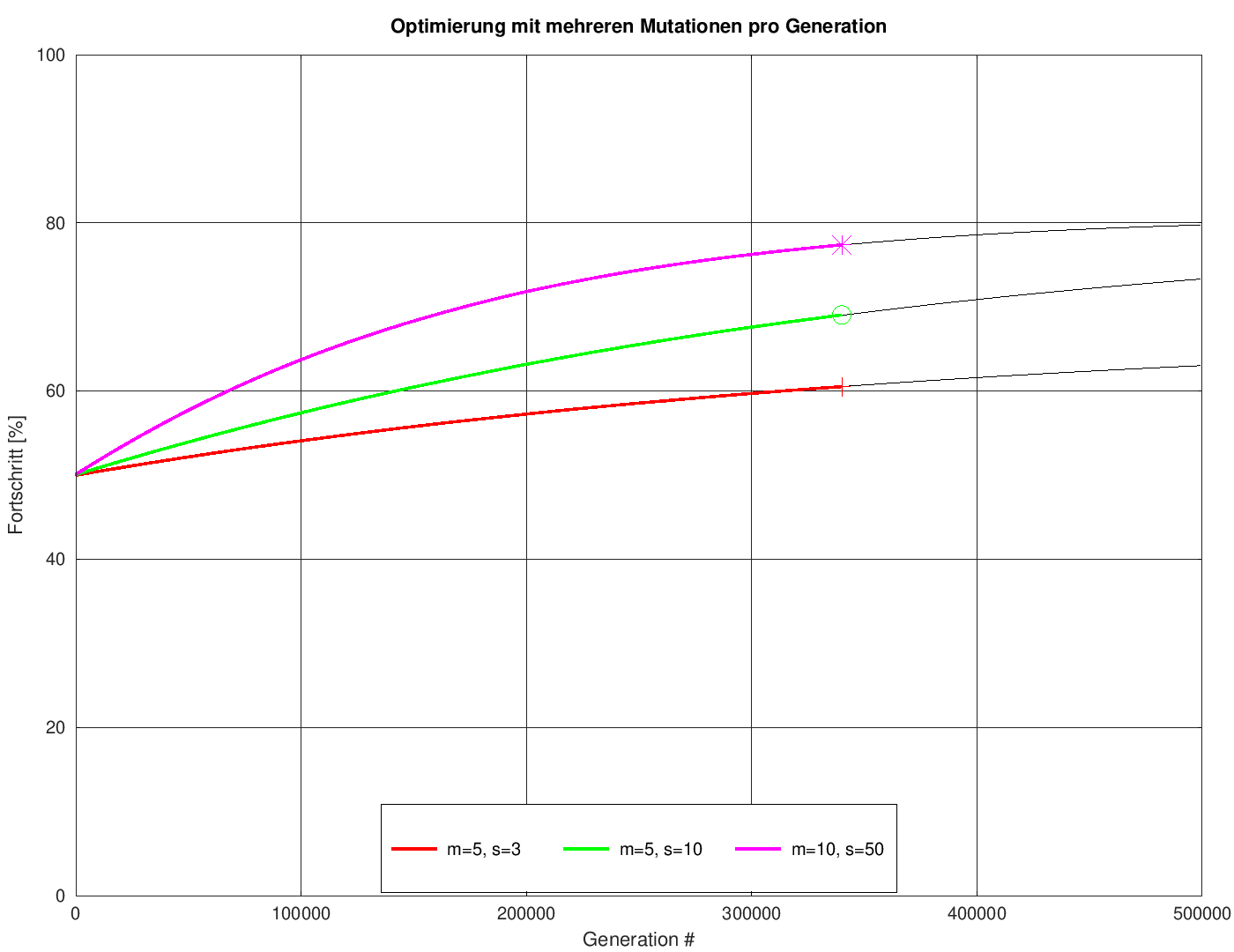
Fazit: Die Kurven sind bis auf Strichstärke deckungsgleich. Daraus kann man die bererchtigte Hoffnung ableiten, dass die Betrachungen korrekt sind.
Der Vollständigkeit halber ein Vergleich der erzielten Bildqualitäten nach der gleichen Zahl von Generationen (340000), was dem Endpunkt der oben gezeigten farbigen Linien entspricht.

Geschwindigkeit und Aufwand
So man diese simple Form eines Evolutionsverfahren zu technischen Zwecken einsetzen will, stellt sich nun die Frage, wie hoch man die Mutationsrate wählen sollte. Wie schon im letzten Kapitel, bei dem wir uns auf eine einzige Mutation pro Generation beschränkt haben, müssen wir wieder zwischen zwei leicht verschiedenen Fragestellungen unterscheiden:
- Wir können vielleicht die Fitnessfunktionen aller Individuen parallel auswerten, etwa wie das in Fall der biologischen Evolution der Fall ist. In diesem Fall interessiert und der Fortschritt pro Generation, was ich im folgenden wieder "Geschwindigkeit" nennen werde.
- Vielleicht können aber die Fitnessfunktionen nur nacheinander berechnet werden (etwa bei Berechnung mittels eines Single-Core-Prozessors) oder wir müssen für jede einzelne Auswertung extra bezahlen. In diesem Fall ist die Zahl der Generationen eher bedeutunglos. Es interessiert uns eher der Aufwand, der der Gesamtzahl von ausgewehrteten Fitnessfunktionen bzw. Individuen entspricht.
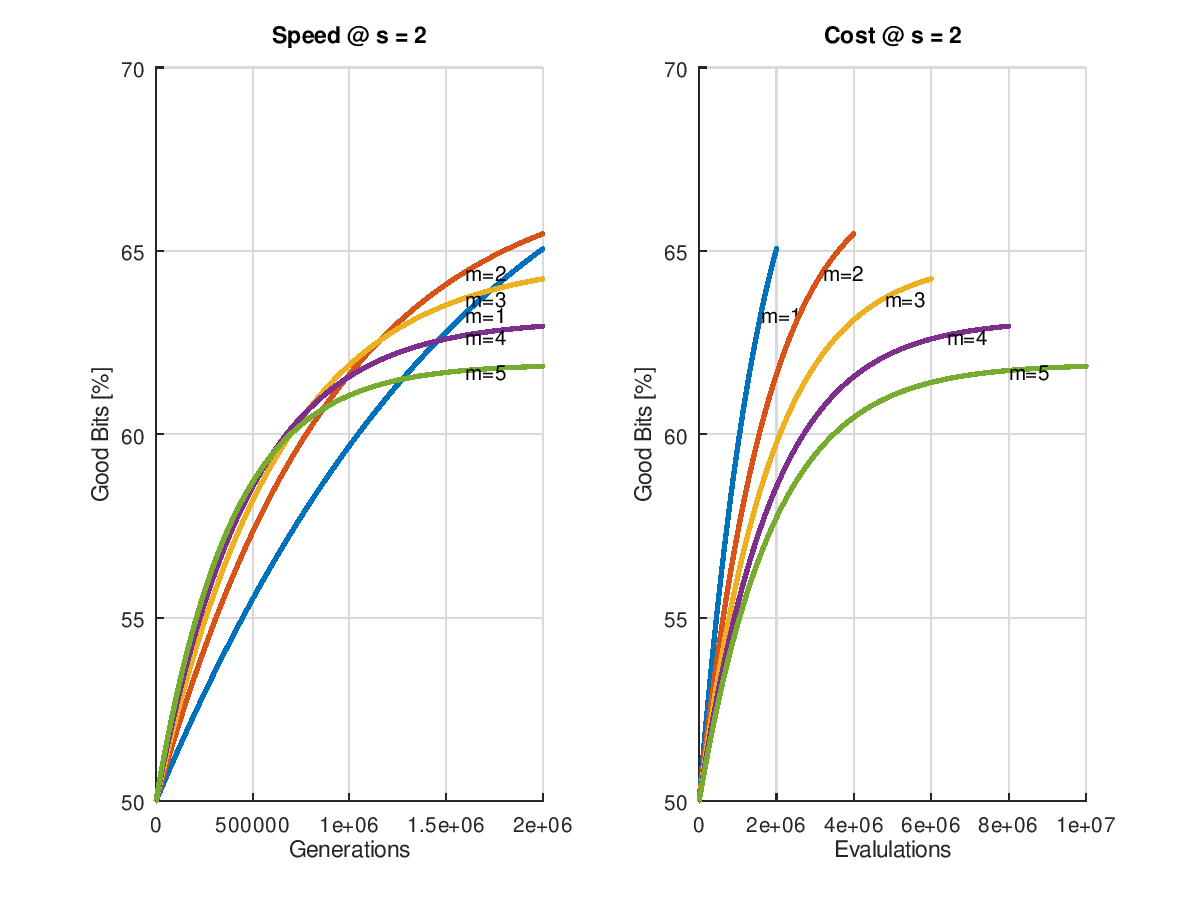
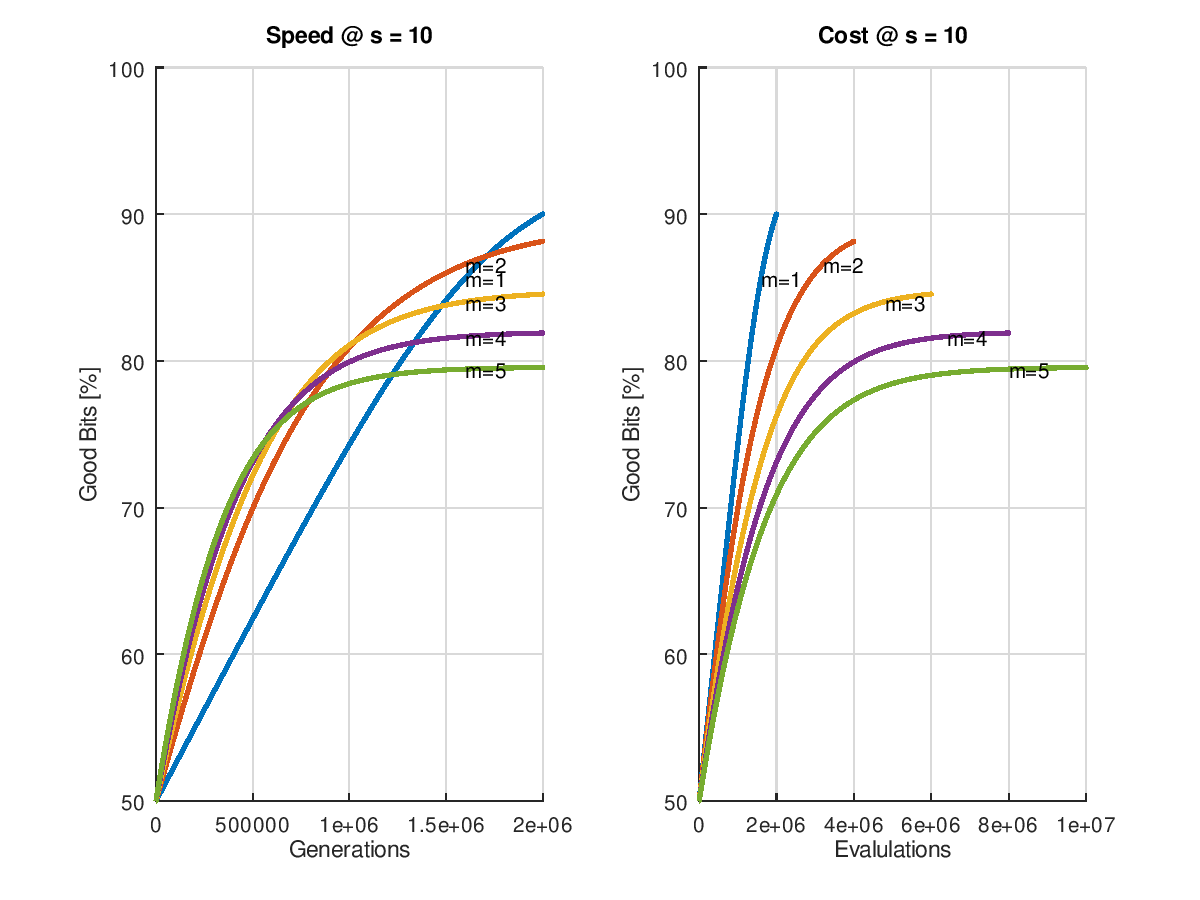
(Wie entstehen die Grafiken? => diesem Link folgen.)
Betrachtet man nun den anfänglichen Erfolg, wenn man mit einer 50% Ursuppe startet, so erkennat man dass die erzielbare Geschwindigkeit mit der Zahl der Mutationen pro Generation ansteigt. Leider hält dieser Zustand nicht dauerhaft an. Umso höher die Zahl der Mutationen, umso früher flacht die Kurve ab, was angesichts der schon gemachten Vorhersage über die erzielbare Qualität zu erwarten war. Die geht ja bekanntlich mit höherer Mutationszahl zurück. Immerhin könnte man wieder einen adaptiven Algorithmus entwickeln, der mit hoher Mutationsrate startet und sie später immer weiter zurücknimmt, sobald die Performance der Optimierung nachlässt.
Sehr eindeutig zu erkennen ist aber auch, dass nicht nur das Endergebnis bei der kleinmöglichen Mutationsrate am besten, sondern auch der Aufwand an geringsten ausfällt. Die Linie mit ist zu jedem Zeitpunkt links und oberhalb von allen anderen, also billiger und besser!
Fazit: Wer sein Problem nicht parallelisieren kann, fährt mit der kleinstmöglichen Mutationsrate grunsätzlich am besten.